
TLDR: ParparVM is now up to 2.8x faster, and produces binaries that are 15%-20% smaller than before.
If you build your app for iOS today, you may notice a performance boost due to some improvements to ParparVM – the AOT compiler we use to build Codename One apps for iOS. Read on for a short history of ParparVM, as well as some details about these improvements.
A Brief History Of ParparVM
In the beginning, Codename One used XMLVM to build apps for iOS. It worked by converting Java byte-codes into its own XML representation, and then converting that XML into C-code. Unfortunately XMLVM was an academic project, and was announced in 2014 that development on it would be discontinued. We were faced with a choice. Do we continue to use XMLVM and simply support it ourselves, or do we migrate to something else. At the time RoboVM was an exciting new technology that compiled Java to LLVM and could produce iOS apps. I had also created a proof of concept port using Avian, an AOT compiler for Java that could produce iOS binaries. A fourth option, which seemed overly ambitious at the time, was to create our own tool from scratch. Ultimately, that is the avenue that was chosen, and ParparVM was born.
Why Didn’t We Choose Avian or RoboVM?
At the time it may have seemed like a logical choice to go with RoboVM, but this was deemed not an option because it was extremely important that we be able to use Apple’s official tool-chain for building apps. That would ensure that we wouldn’t hit a dead end. A key requirement of ParparVM was to produce actual X-code projects that could be built using Apple’s tool-chain. This had several benefits. In addition to “future-proofing” us in the case that Apple might start rejecting apps that didn’t use the official tools, it provided the ability to use Apple’s mature tools for profiling and debugging if needed.
In the Beginning: A Stack-Based VM in C
In the beginning ParparVM generated a faithful representation of java’s stack-based virtual machine in C-code. This made it very easy to verify the correctness of the code. Using our own stack also enabled us to implement a highly efficient, concurrent garbage collector that would avoid pauses. XMLVM had used the Boehm conservative garbage collector that would need to “stop the world” to collect garbage. ParparVM, in contrast, uses its own concurrent Mark-sweep garbage collector that very nearly eliminates all such pauses.
Once this was stable, we started introducing a few optimizations for common sequences of stack instructions. E.g. A statement like:
return 1;
in Java would produce bytecodes to:
Add “1” to the stack.
Pop “1” off the stack and return it.
Clearly, it would be better for the resulting C code to simply return 1, just like the Java code, so ParparVM would optimize cases like this to do just that.
However there were multitudes of other cases that we left unoptimized. E.g. The instruction:
int result = 20 + this.height * width;
would generate 7 stack operations. The C-compiler (LLVM) would help optimize this a bit, but there is only so much it could do.
Things like this would cause ParparVM to perform poorly in some micro benchmarks, but it didn’t factor in to actual perceived app performance and user experience because most of the critical code (especially related to UI and graphics) is written in native C code, and 90% of CPU time is spent in that code.
Implementing Key Methods in Native C
Once ParparVM was stable, we started optimizing common use cases by implementing “important” methods in native code. Many Math, String, and StringBuilder methods were implemented in native C since those are core to many applications. As users presented use cases that didn’t perform well (usually in crunching large amounts of data), we would profile and ease the bottlenecks by implementing more things natively.
By the time Codename One 3.4 was released, general performance had improved dramatically. Native implementations of String methods made the most common data tasks (parsing JSON and XML) almost on par with native code. If an app needed additional performance for certain tasks, they could always use native interfaces to get a boost.
There remained much low-hanging fruit for optimizing the actual generated C-code produced by ParparVM, this was placed on the back-burner since performance for key use cases had already been optimized with native code directly – and perceived performance, which related mostly to graphics rendering, did not depend on java code to a great extent.
Present Day: A New Reason to Revisit Optimizations
ParparVM remained largely unchanged and stable through Codename One 3.5 and 3.6, but recently we ran into an issue where clang was having difficulty compiling very large C methods. This gave us some motivation to optimize some of the generated C-code again. This time, the impetus was a desire to reduce the size of the generated code.
The use case that we were provided with included hundreds method invocations to construct a GeneralPath. Each java instruction looked like:
((GeneralPath) shape).curveTo(105.305275, 167.71288, 105.24711, 168.68971, 105.457146, 169.88364);
The resulting C-code for each of these would be over 20 lines of code. It would add the shape and each of the numbers to the stack, then call the function which would unwind the stack.
I was able to reduce this down to the point where the C-code was pretty much identical to the Java code (disregarding method naming conventions), and lines of code in the method were reduced by 80%. This solved Clang “hanging” problem, and improved performance.
Let’s do ALL the Optimizations!
Fixing the code size issue in this special case made me realize just how easy it would be to implement all the optimizations. So I set to work trying to eliminate as many stack operations as possible. In many cases now, the resulting C code is line-for-line the same as the original Java code. Cutting out the middle-man (the stack), I hoped, would also allow LLVM to optimize the code more aggressively.
Benchmarks
I hoped that my optimizations would produce a noticeable difference in performance. I would have been happy with a 25% improvement. So I set up a micro benchmark to see how it compared.
To start with, I created a method that calculates the largest prime number less than some large value. Then I created a benchmark that would run this method 100 times on some large value. The method is as follows:
public static final int getMaxPrimeBefore(int limit) {
boolean[] sieve = new boolean[limit];
Arrays.fill(sieve, true);
sieve[0] = false;
sieve[1] = false;
int largest = 0;
for (int p = 2; p < limit; p++) {
if (sieve[p]) {
largest = p;
for (int np = p * 2; np < limit; np += p) {
sieve[np] = false;
}
}
}
return largest;
}
This would test performance on local variable usage, array element access, arithmetic, and if/else branches. Running this benchmark on my iPhone 6S using Codename One 3.6 (i.e. before the recent optimizations) resulted in an average time of 231ms to run getMaxPrimeBefore(4000000). Running it using the latest Codename One (i.e. after optimizations), this time was reduced to 113ms. That is a performance increase of over 2x.
Now, to test out performance of static variable access, I modified the benchmark slightly to use static variables instead of local variables:
private static boolean[] staticSieve;
private static int staticLargest;
private static int staticP;
private static int staticNp;
private static int staticLimit;
public static final int getMaxPrimeBeforeStaticVars(int limit) {
staticLimit = limit;
staticSieve = new boolean[staticLimit];
Arrays.fill(staticSieve, true);
staticSieve[0] = false;
staticSieve[1] = false;
staticLargest = 0;
for (staticP = 2; staticP < staticLimit; staticP++) {
if (staticSieve[staticP]) {
staticLargest = staticP;
for (staticNp = staticP * 2; staticNp < staticLimit; staticNp += staticP) {
staticSieve[staticNp] = false;
}
}
}
return staticLargest;
}
Running this benchmark on Codename One 3.6 (before optimizations) resulted in an average time of 380ms. On that latest Codename One (i.e. after optimizations) it ran in 135ms. That is an speed increase of over 2.8x.
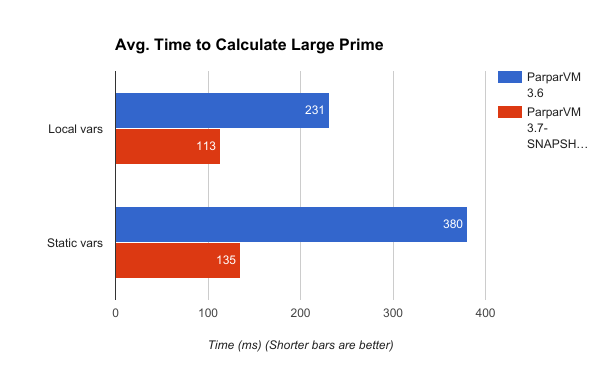
There are obviously many more benchmarks that can be written that would cover more cases, but things are looking good so far. Does this mean that your app will perform 2.8x better? Probably not. As I mentioned above, most of the user experience is dictated by graphics performance and responsiveness (scrolling, rendering, etc..), and this is already done mostly in native code. However, for processor intensive tasks like number crunching, or data parsing, you are likely to see real performance gains. Code that is heavy on 2D graphics, shapes, and transforms may also see noticeably improvement.
Even if these gains aren’t readily noticeable in your app, it is nice to know that if you crank out some extra performance for something in your app, you can do it without having to delve into native interfaces.
Code Size and App Size
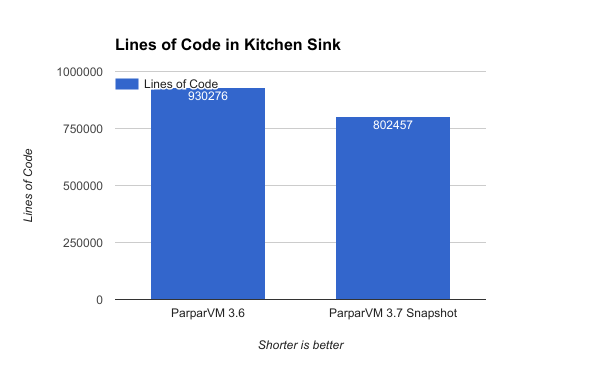
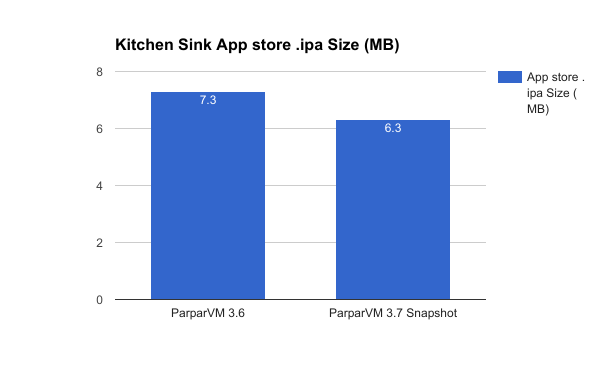
These optimizations also yielded smaller apps. I built the Kitchen Sink app using Codename One 3.6 and with the latest to see if there was any difference in the size of code. It produced 15% to 20% improvements on both of these fronts. With 3.6, Kitchen Sink resulted in 930276 lines of C code (in .m files), and an App store IPA file size of 7.3MB. Buliding it with the latest Codename One resulted in 802457 lines of code, and an IPA file size of 6.3MB. That is 16% fewer lines of code and a final app size that is also 16% smaller. Not dramatic, but substantial.
Conclusion
These early benchmarks look promising, and I fully expect similar gains across the board. It is worth mentioning (again), however, that microbenchmarks like this don’t correlate directly to user experience. If your app isn’t doing anything CPU intensive in Java code, then you probably won’t notice a difference, since most critical UI functionality is already implemented in native code. However, if you’re doing a lot of data crunching in your app, or drawing a lot of shapes with transforms, then these optimizations are likely to be more tangible to you.
Feel free to create your own benchmarks comparing Codename One 3.6 with the latest. I’m interested in hearing about your results.
Archived Comments
This post was automatically migrated from the legacy Codename One blog. The original comments are preserved below for historical context. New discussion happens in the Discussion section.
Jérémy MARQUER — February 14, 2017 at 1:21 pm (permalink)
Really nice !!
I think it could also be noticeable on older devices …
bryan — February 14, 2017 at 8:05 pm (permalink)
Great work Steve. CN1 is getting better and better, congrats to all.
Gareth Murfin — February 9, 2019 at 4:49 pm (permalink)
Great work Steve – certainly in the last year or so cn1 has felt way faster
Discussion
Join the conversation via GitHub Discussions.